Will 2014 be the year that you take a huge volume of texts and run them through an algorithm to detect their themes? Because significant hurdles to humanists’ ability to analyze large volumes of text have been or are being overcome, this might very well be the year that text mining takes off in the digital humanities. The ruling in the Google Books federal lawsuit that text mining is fair use has removed many concerns about copyright that had been an almost insurmountable barrier to obtaining data. Another sticking point has been the question of where to get the data. Until recently, unless researchers digitized the documents themselves, the options for humanities scholars were mostly JSTOR’s Data for Research, Wikipedia and pre-1923 texts from Google Books and HathiTrust. If you had other ideas, you were out of luck. But within the next few months there will be a broader array of full-text data available from subscription and open access databases.
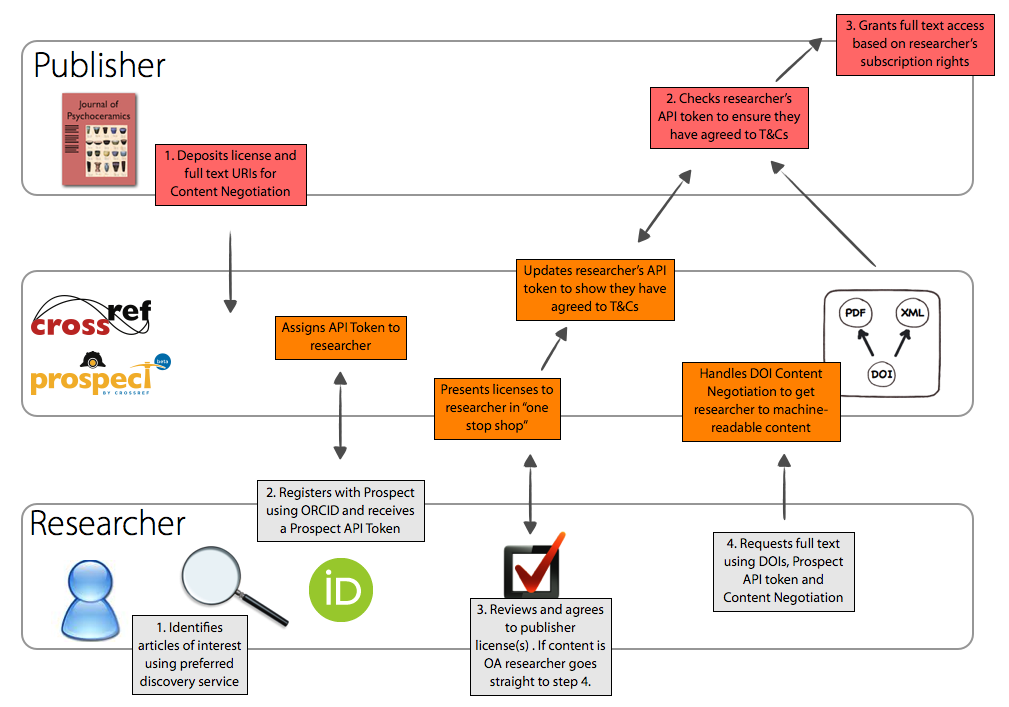
CrossRef, the organization that manages Digital Object Identifiers (DOIs) for database publishers, has a pilot text mining program, Prospect, that has been in beta since July 2013 and will launch early this year. There is no fee for researchers who already have subscription access to the databases. To use the system, researchers with ORCID identifiers log in to Prospect and receive an API token (alphanumeric string). For access to subscription databases, Prospect displays publishers’ licenses that researchers can sign with a click. After agreeing to the terms, they receive a full-text link. The publisher’s API verifies the token, license, and subscription access and returns full-text data subject to rate limiting (e.g. 1500 requests per hour).
Herbert Van de Sompel and Martin Klein, information scientists who participated in the Prospect pilot, say “The API is really straightforward and based on common technical approaches; it can be easily integrated in a broader workflow. In our case, we have a work bench that monitors newly published papers, obtains their XML version via the API, extracts all HTTP URIs, and then crawls and archives the referenced content.”
The advantage for publishers is that providing access to an API may stop people from web scraping the same URLs that others are using to gain access to individual documents. And publishers won’t have to negotiate permissions with many individual researchers. Although a 2011 study found that when publishers are approached by scholars with requests for large amounts of data to mine they are inclined to agree, it remains to be seen how many publishers will sign up for the optional service and what the license terms will be. Interestingly, the oft-maligned Elsevier is leading the pack having made its API accessible to researchers during the pilot phase. Springer, Wiley, Highwire and the American Physical Society are also involved.
Details about accessing the API are on the pilot support site and in this video. CrossRef contacts are Kirsty Meddings, product manager [[email protected]] and Geoffrey Bilder, Director of Strategic Initiatives [[email protected]].