Will 2014 be the year that you take a huge volume of texts and run them through an algorithm to detect their themes? Because significant hurdles to humanists’ ability to analyze large volumes of text have been or are being overcome, this might very well be the year that text mining takes off in the digital humanities. The ruling in the Google Books federal lawsuit that text mining is fair use has removed many concerns about copyright that had been an almost insurmountable barrier to obtaining data. Another sticking point has been the question of where to get the data. Until recently, unless researchers digitized the documents themselves, the options for humanities scholars were mostly JSTOR’s Data for Research, Wikipedia and pre-1923 texts from Google Books and HathiTrust. If you had other ideas, you were out of luck. But within the next few months there will be a broader array of full-text data available from subscription and open access databases.
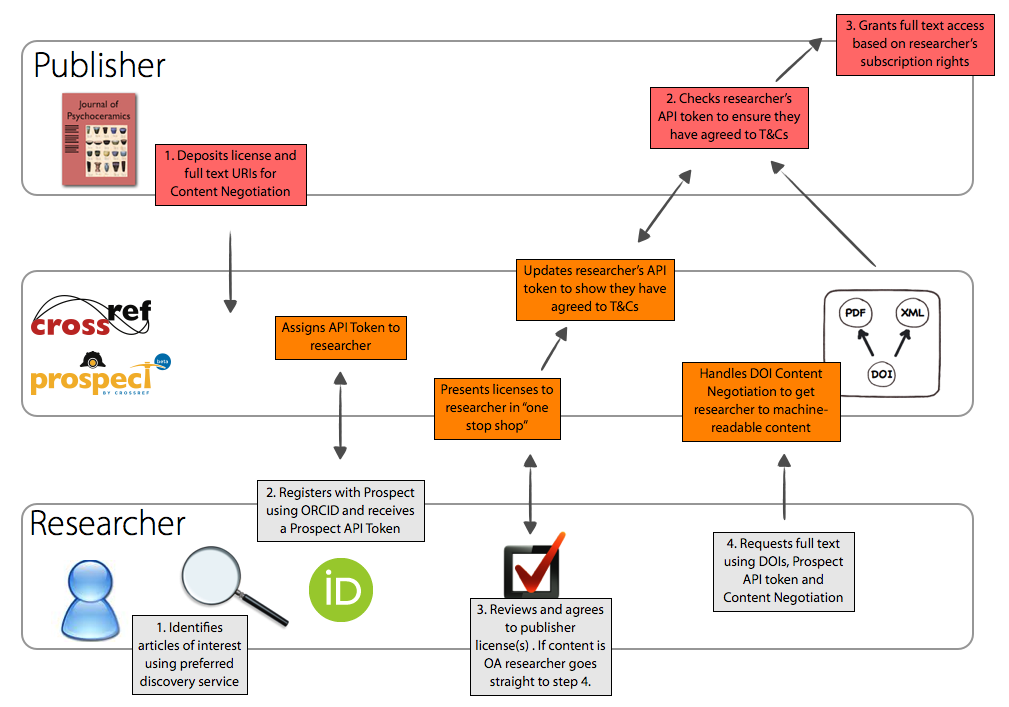
CrossRef, the organization that manages Digital Object Identifiers (DOIs) for database publishers, has a pilot text mining program, Prospect, that has been in beta since July 2013 and will launch early this year. There is no fee for researchers who already have subscription access to the databases. To use the system, researchers with ORCID identifiers log in to Prospect and receive an API token (alphanumeric string). For access to subscription databases, Prospect displays publishers’ licenses that researchers can sign with a click. After agreeing to the terms, they receive a full-text link. The publisher’s API verifies the token, license, and subscription access and returns full-text data subject to rate limiting (e.g. 1500 requests per hour).
Herbert Van de Sompel and Martin Klein, information scientists who participated in the Prospect pilot, say “The API is really straightforward and based on common technical approaches; it can be easily integrated in a broader workflow. In our case, we have a work bench that monitors newly published papers, obtains their XML version via the API, extracts all HTTP URIs, and then crawls and archives the referenced content.”
The advantage for publishers is that providing access to an API may stop people from web scraping the same URLs that others are using to gain access to individual documents. And publishers won’t have to negotiate permissions with many individual researchers. Although a 2011 study found that when publishers are approached by scholars with requests for large amounts of data to mine they are inclined to agree, it remains to be seen how many publishers will sign up for the optional service and what the license terms will be. Interestingly, the oft-maligned Elsevier is leading the pack having made its API accessible to researchers during the pilot phase. Springer, Wiley, Highwire and the American Physical Society are also involved.
Details about accessing the API are on the pilot support site and in this video. CrossRef contacts are Kirsty Meddings, product manager [kmeddings@crossref.org] and Geoffrey Bilder, Director of Strategic Initiatives [gbilder@crossref.org].
Thank you for this great post! The NYPL Digital Collection recently opened up their API . I’m still trying to gain a firm understanding of what API access means exactly. Your post is very informative and full of great links. You mention researchers that have subscription access to databases (either via an institution like NYPL or through the GC) will be abe to use Prospect. But registration with Orcid is required first, right? Also, I enjoyed the chart that explains the relationship break down of researcher, database and publisher (visuals are always helpful for me). Thanks!
For some reason reason this link wasn’t included in my comment: The New York Public Library Digital Collections API http://api.repo.nypl.org/
Thanks for the post. I thought I’d just clarify one or two things that we (CrossRef) have probably not explained well so-far.
The first is that the core of the TDM “API” (née “Prospect”) is little more than the inclusion of some new elements (licensing information and links to full text) in our metadata schema. CrossRef metadata is, in turn, available via CrossRef’s existing free APIs (Content negotiation, OpenURL, REST). This by itself will provide a common mechanism for TDM researchers to access content across CrossRef publishers regardless of their business models (e.g. open access, subscription, for-profit, non-profit). Obviously, participating Open Access publishers will have to do little other than deposit the required metadata elements in order to enable TDM via this mechanism. (Indeed, Hindawi Publishing, is already doing so.) But the same is true for any publishers who include TDM in their subscription agreements. CrossRef is increasingly seeing its subscription publisher members just include TDM terms in their new subscription agreements.
But some publishers do not yet include TDM in their subscription agreements and/or have existing agreements that they need to amend in order to allow TDM. In these cases is is untenable for researchers to have to negotiate multiple bilateral agreements with publishers, so CrossRef has also built the above-mentioned click through service. So the second thing to clarify is that usage of this click-through service will only be required by some publishers, not all. We’ve got some updated workflow diagrams that try to convey this distinction here:
http://prospectsupport.labs.crossref.org/tdm-workflow/
Finally, Melanie asks if ORCID registration is required to use the TDM API. The answer is “no”, – not for general use of the TDM API. An ORCID is only required if the researcher needs to use the click-through service in order to agree to specific publisher license and/or terms & conditions. We do this largely because we expect that researchers don’t want to have to fill-out yet another form listing their affiliations, contact details, etc. (more selfishly- we also don’t want to have be responsible for storing and updating this information :-)). In practice, we don’t expect this to be a burden. ORCID registration is free, very easy and will ultimately prove useful to researchers who are sick of providing the same information when they submit journal articles, grant applications, etc.
Finally, we should note beyond the technical and logistical issues, there are policy issues that are making TDM difficult and contentious. CrossRef does not involve itself policy issues, but we note that often the technical, logistical and policy issues are conflated. We hope that, by resolving (or at least reducing) the technical/logistical issues, we can allow others to focus on the more substantive policy issues.
Again, thanks for a great summary.
Geoffrey, thanks for the more detailed explanation. I have a few more questions. If scholars want to engage in text mining now, or in the near future, how will they be able to find out which publishers are making data accessible? Is there a list of publishers participating in Prospect, and/or publishers that are making the data accessible without a license? And where would scholars actually go to access the data? To the publisher’s API? Is there a list of publishers’ APIs?
Hi Eileen. Once the system is launched, publishers will probably indicate that they are participating on their web respective sites. We are not yet sure how they will do this. We may provide them with a badge or a logo to display. CrossRef will also have a page listing publishers who are participating. Similarly CrossRef will have an easy way for you to tell which publishers require the click-through agreements.
And while on the topic of click-throughs… I should probably make the (incredibly pedantic, forgive me) point that I can’t imagine any publisher making their articles accessible “without a license.” Some will support well-known licenses like CC-BY, others will have proprietary licenses. The issue we are trying to address is whether the publisher requires an extra step of clicking through an addendum to any existing license. This addendum might include license clarifications or extra T&Cs concerning use of the API (e.g. rate-limiting, etc.). I should also clarify that, in the cases where there is such a click-through, the researcher will only need to “accept” the respective click-through once- after that they can just use the API key they are given to prove that they have already accepted relevant click-throughs.
Finally, you ask “where would the scholar go to actually access the full text?” When the researcher accesses the CrossRef DOI using content negotiation, the returned CrossRef metadata will include URIs which point directly to the full text representations the publisher is making available. These are most likely going to be on the publisher’s site. If the content is open access (which you will be able to determine by looking at the license information returned in the CrossRef metadata), then the scholar can simply retrieve the full text URIs. If the content is on a subscription-based publisher’s site and is not open access, then the ability of the scholar to retrieve the DOI will be controlled by the access control system on the publisher’s site- which means that subscribers will be able to access it and non-subscribers will not. So ultimately there is no need to use a specific “publisher API”- the same technique will work across participating publishers.
Pingback: CrossRef’s Prospect API // Days in the Life of a Librarian // Blog Network // University of Notre Dame